Unit 2: ARTIFICIAL INTELLIGENCE
Acquiring information on artificial intelligence and knowledge engineering is
|
Domain |
Description |
Task performed |
Tools |
|
Expert system |
Uses formal logic rules to simulate human reasoning |
Answering and solving complex problems and
repetitive tasks |
Experta or pyknow (using Python P/L) clips (using C
P/L), pyke, nools |
|
Supervised machine learning |
An algorithm that learn from labelled data |
Classification, prediction |
Tensorflow, keras, sci-kit learn, xgboost, pytorch,
pandas, numpy |
|
Unsupervised machine learning |
An algorithm that learn from unlabelled data |
Segmentation, text classification, recommending
content |
Tensorflow, keras, sci-kit learn, xgboost, pytorch |
|
Reinforcement machine learning |
Learn from interactions with dynamic environment |
Planning, online advertising, process control |
PyBullet, dopamine |
|
Artificial Neural Network (ANN) |
Inspired and similar to the working of biological
neurons and allow complex functions to be modelled from data |
Image recognition, natural language processing (NLP) |
Tensorflow, keras, sci-kit learn, MXNET |
|
Natural Language Processing (NLP) |
Uses text analysis techniques to understand human
language |
Language translation, text generation, text
prediction, speech recognition, sentiment analysis |
Nltk, spacky, textblob |
|
Multi-agent systems |
Simulate the behavoiur of several agents such as
robots or people |
Coordination and planning |
Mesa spade |
|
Data mining and Data warehousing |
It sorts, uncovers, identify patterns and
relationship that can solve business problem through large datasets |
Biological data analysis, time series analysis, prediction,
clustering, intrusion detection, predictive and descriptive data mining tasks |
RapidMiner, kNime, Apache Hadoop, Tensorflow, keras,
sci-kit learn |
What is Machine Learning?
Task, input, output, algorithm done with the three (3) types of ML with simple definition in their approach
What is Python Library?
What is Dataset?
Installing and Importing libraries (Using pandas as an example)
Installing: To install Pandas enter pip install pandas or pip3 install pandas in the terminal or command line.
Three basic steps to make your dataset usable for your machine learning (ML) model
Step 1: Data collection means to get the data either raw (by preparing the dataset yourself) or getting the dataset from the internet.
Step 2: Data preprocessing means that you make sure the data in the dataset is clean and relevant for the specific task. Eliminate issues like missing values, incorrect format etc. Preprocessing data before applying it to a machine learning algorithm / model is important in the ML workflow. It helps to improve the accuracy, reduce the time and resources required to train the model, prevent overfitting, and helps to interpret the model easily.
Step 3: Data annotation means you explain to the ML model what the dataset contains by adding meaningful labels to each data, then you use the annotated dataset to train and test your ML model for prediction
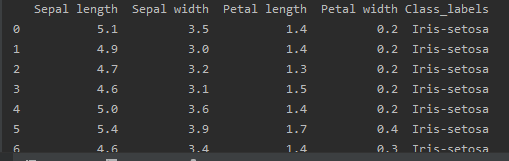
import pandas as pd columns = ['Sepal length', 'Sepal width', 'Petal length', 'Petal width', 'Class_labels'] # Load the data df = pd.read_csv('iris.data', names=columns) # prints first 5 rows by default print(df.head()) # prints first 10 rows print(df.head(10)) |
OUTPUT OF IRIS DATASET: FIRST 10 ROWS FOR OBSERVATION
Workflow showing integral steps to implement Machine Learning

PYTHON IMPLEMENTATION FOR IRIS CLASSIFICATION
Version
that worked
Pip show
numpy #to display the version of numpy library on the command prompt
Pip install
numpy==1.20.2
When you
install matplotlib, it automatically downloads latest version of numpy (it
complains of float, float32, and int), uninstall it, and specify the numpy
version that will work for your system.
Requirements
Numpy:
1.20.2
Matplotlib:
3.7.1
Pandas
Sklearn
Support Vector Machine (SVM) Algorithm
You can use pycharm to implement the codes and install the required libraries BUT if you want to use your phone, you can use Google Colab (it contains all the required libraries, all you need do is just to type the "import" keyword followed by the library name)
Software Requirement
This project is implemented in Python (version 3.8.0)
and pycharm IDE. The other libraries used throughout the project are described
below:
Pandas: Pandas is an open source library that provides tools for data mining and analysis using Python. It is mainly used to load and prepare the data for consumption by specific machine learning algorithms.
NumPy:
NumPy is a Python library that can handle multidimensional data and perform
scientific and mathematical operations on the data. NumPy was used in this
project as an accessory to the Pandas library to perform some basic
mathematical operations.
Matplotlib: Matplotlib is an open-source Python visualization library used for visualizing data from a given data in form of graphics such as bar chart, pie chart, line graph etc.
Streamlit: Streamlit is an open source library, a Python framework and dashboarding tool for building analytical responsive web interfaces, and allows python visualization, analysis and machine learning. You use Streamlit framework if you can your program to have a user interface (UI) rather than using the Console inteferace (Command Line Interface, CLI) to interact with the program.
Step 1 – Import each Library:
Phase 1
|
# phase 1 import numpy as np import
matplotlib.pyplot as plt import seaborn as
sns import pandas as pd from sklearn.metrics
import accuracy_score from sklearn.svm
import SVC from
sklearn.model_selection import train_test_split |
Step 2 – Load the data:
Phase 2
|
columns = ['Sepal
length', 'Sepal width', 'Petal length', 'Petal width', 'Class_labels'] # Load the data df =
pd.read_csv('iris.data', names=columns) # prints first 5
rows by default print(df.head()) # prints first 10
rows print(df.head(10)) |
Step 3 – Preprocess and visualize the dataset:
TIP: When
the runs, it shows the seaborn image first, close it, to see the second image.
Phase 3
|
# Some basic statistical
analysis about the data print(df.describe()) |
Phase 4
It's a good practice to visualize the dataset before training and testing the required model / classifier.
|
# Visualize the whole dataset sns.pairplot(df,
hue='Class_labels') plt.show() |
Phase 5
|
# Separate features
and target data = df.values X = data[:,0:4] #set range from 0 to 3 Y = data[:,4] # Calculate average
of each features for all classes # this is a list
comphrension embedded with nested for loops Y_Data =
np.array([np.average(X[:, i][Y==j].astype('float32')) for i in range
(X.shape[1]) for j in (np.unique(Y))]) #to indicate 4
inputs and 3 species Y_Data_reshaped =
Y_Data.reshape(4, 3) Y_Data_reshaped =
np.swapaxes(Y_Data_reshaped, 0, 1) X_axis =
np.arange(len(columns)-1) width = 0.25 # Plot the average plt.bar(X_axis,
Y_Data_reshaped[0], width, label = 'Setosa') plt.bar(X_axis+width,
Y_Data_reshaped[1], width, label = 'Versicolour') plt.bar(X_axis+width*2,
Y_Data_reshaped[2], width, label = 'Virginica') plt.xticks(X_axis,
columns[:4]) plt.xlabel("Features") plt.ylabel("Value
in cm.") #plt.legend(bbox_to_anchor=(1.3,1)) plt.legend(bbox_to_anchor=(.25,
1.1), loc=2, borderaxespad=0.) plt.show() |
Step 4 – Train and
test the model:
Phase 6
|
# Split the data to
train and test dataset. X_train, X_test,
y_train, y_test = train_test_split(X, Y, test_size=0.2) # Support vector
machine algorithm svn = SVC() svn.fit(X_train,
y_train) |
Step 5 – Make prediction:
Phase 7
|
# Predict from the
test dataset predictions =
svn.predict(X_test) # Calculate the
accuracy to 3 decimal places and multiply by 100 print("The
accuracy of the SVM is {:.3f} %".format(accuracy_score(y_test,
predictions))) #testing the model X_new =
np.array([[3, 2, 1, 0.2], [ 4.9, 2.2,
3.8, 1.1 ], [ 5.3, 2.5, 4.6, 1.9 ]]) #new test by me #X_new = np.array([[4.3, 2.0, 1.0, 0.1], [ 7.9, 4.4, 6.9, 2.5 ], [ 5.4, 3.5, 1.3, 0.2 ]]) #Prediction of the
species from the input vector prediction =
svn.predict(X_new) print("Prediction
of Species: {}".format(prediction)) |
#CODE MODIFIED BY AJALA |
|
#
phase 1 import
numpy as np import
matplotlib.pyplot as plt import
seaborn as sns import
pandas as pd import
warnings warnings.simplefilter("ignore")
#
phase 2 columns
= ['Sepal length', 'Sepal width', 'Petal length', 'Petal width',
'Class_labels'] #
Load the data df
= pd.read_csv('iris.data', names=columns) #print(df.head(10))
#
phase 3 #
Some basic statistical analysis about the data #print(df.describe())
#
phase 4 sns.pairplot(df,
hue='Class_labels') #hue
parameter is used to visualize the data of different categories in one plot #sns.pairplot(df,
hue="Class_labels", height = 2, palette = 'colorblind'); plt.show()
#phase
5 #
data preprocessing and label encoding #
change categorical data (non-numerical values) to numerical format #import
label encoder from
sklearn.preprocessing import LabelEncoder lbc
= LabelEncoder() df['Class_labels']
= lbc.fit_transform(df['Class_labels']) #display
the preprocessed dataset print(df.head()) #Phase 6 #model
training from
sklearn.model_selection import train_test_split #X
represent the input features df['Sepal length', 'Sepal width', 'Petal
length', 'Petal width'] #
we drop the columns not related to the input features X
= df.drop(columns = ['Class_labels']) #output column, add Class_labels column to the dataframe(df) Y
= df['Class_labels']
#test
and split xtrain,
xtest, ytrain, ytest = train_test_split(X, Y, test_size= 0.30)
#import
the model to be used from sklearn #you
can test other models too #
such as decision tree, svm, randomForest etc. from
sklearn.linear_model import LogisticRegression selectmodel
= LogisticRegression() selectmodel.fit(xtrain,
ytrain)
#print
the accuracy of the model or algorithm selected #store
the prediction result in a variable called prediction prediction
= selectmodel.score(xtest, ytest)*100 print("Accuracy::
", prediction)
#phase 7 #test
new input features (by adjusting the features value to value from 0 to 9.9) #testing
the model xnew_input
= np.array([[2.5, 1.2, 1, 0.2], [ 6.4,
2.2, 3.8, 1.1 ], [ 4.2, 2.5, 4.6, 1.9
]]) #Prediction
of the species from the input vector xnewprediction
= selectmodel.predict(xnew_input) print("Prediction
of Species: {}".format(xnewprediction))
|
DATA PREPROCESSING
Data preprocessing is handled by the Pandas python library, data preprocessing involves the following:
- label encoding: to convert non-numerical values into numerical value (because the machine do not understand string of characters except numbers)
- handling missing values: missing values can negatively affect the prediction, hence we can replace missing values using mean, media, mode method.
- selecting appropriate column(s): you can select one or more columns needed for analysis
- performing normalization: this is when a plot diagram shows a left or right skew, so to normalize it, we need to apply log transformation to make the plot a normal distribution as done in statistics
SAMPLE OF HOW TO USE SOME OTHER MODELS (then modify the selected model line of codes section)


Comments
Post a Comment